
建立联合索引有个最左匹配原则,俗话说就是:带头不能死,中间不能断。
打个比方(A,B,C)能匹配A,AB,ABC,但是不能匹配AC和BC。
在项目上,我新建了一个(uuid ,click_number)的索引,用explain看一下:
explain SELECT keyword,click_number FROM songs WHERE `uuid`='0002fd47-feb4-46cd-942a-633f0cdc37ef' ORDER BY click_number desc;
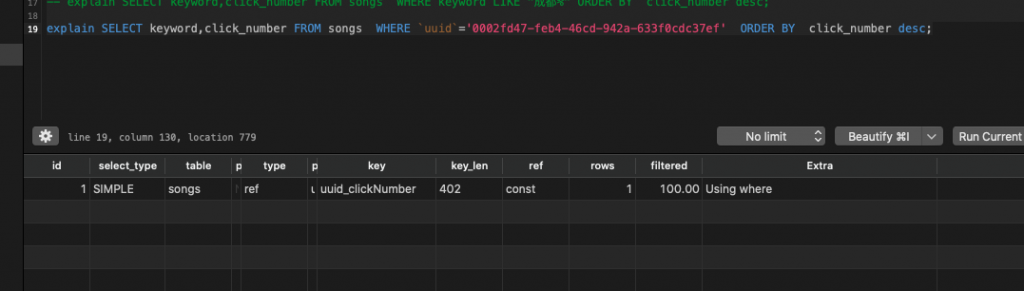
可以看到ref是const常量类型查询,在extra字段是using where,并没有存在额外的负担操作,很棒!
但是,接下来有个需求,因为我是搜索站,要对数据进行模糊查找,并且以点击量作为降序排序(不光是搜索网站,一般的企业后台也会根据会员、订单等模糊搜索并进行排序)
于是我屁颠颠的跑去建立索引,(keyword, click_number),接下来分析一下:
//按照前缀优先匹配规则, keyword和click_number字段应该都可以完美查询
explain SELECT keyword,click_number FROM songs WHERE keyword LIKE "成都%" ORDER BY click_number desc;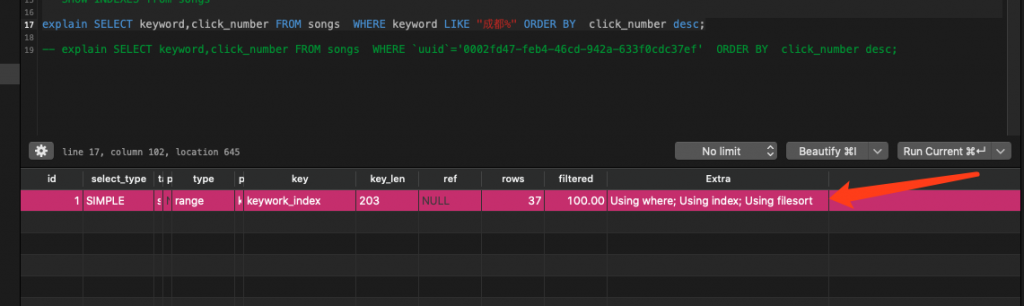
不是说好了做对方彼此的天使吗?为什么会出现filesort?
如果在extra字段发现有using filesort字段,并且表里超过百万行数据,那就上高香求神拜Mysql服务器不要挂掉吧,filesort表示mysql提取数据出来后再放到一块内存里做排序,如果天真无邪纯真可爱的你还使用了select *查询数据,那数据量分分钟挤爆掉sort buffer(我猜的)
思考半小时后.......
得出了一个结论,注意看上图,type是range,说明mysql进行了范围查询(这不废话嘛模糊查询肯定就是范围查询),到这里我恍然大悟,想到了mysql的经典法则:
范围之后全失效!范围之后全失效!范围之后全失效!
所以,即使explain出来有命中的key也不要粗心大意,要留意extra有没有坑
那如果这种情况有没有完美的解决方案呢?暂时没想到,不过还是可以优化的
- 通过限制Limit行数
- 限制select 字段
- 提高sort_buffer等方式让mysql以最优速度运行
毕竟mysql官方提供的这些参数都是很有用的,如果这点小性能mysql都解决不了,那mysql还能活到今天?